About
LOD-a-lot democratizes the access to the Linked Open Data (LOD) Cloud by serving more than 28 billion unique triples from 650K datasets (collected in LOD Laundromat) from a single self-indexed HDT file.
This corpus can be queried online with a sustainable Linked Data Fragments interface, or downloaded and consumed locally.
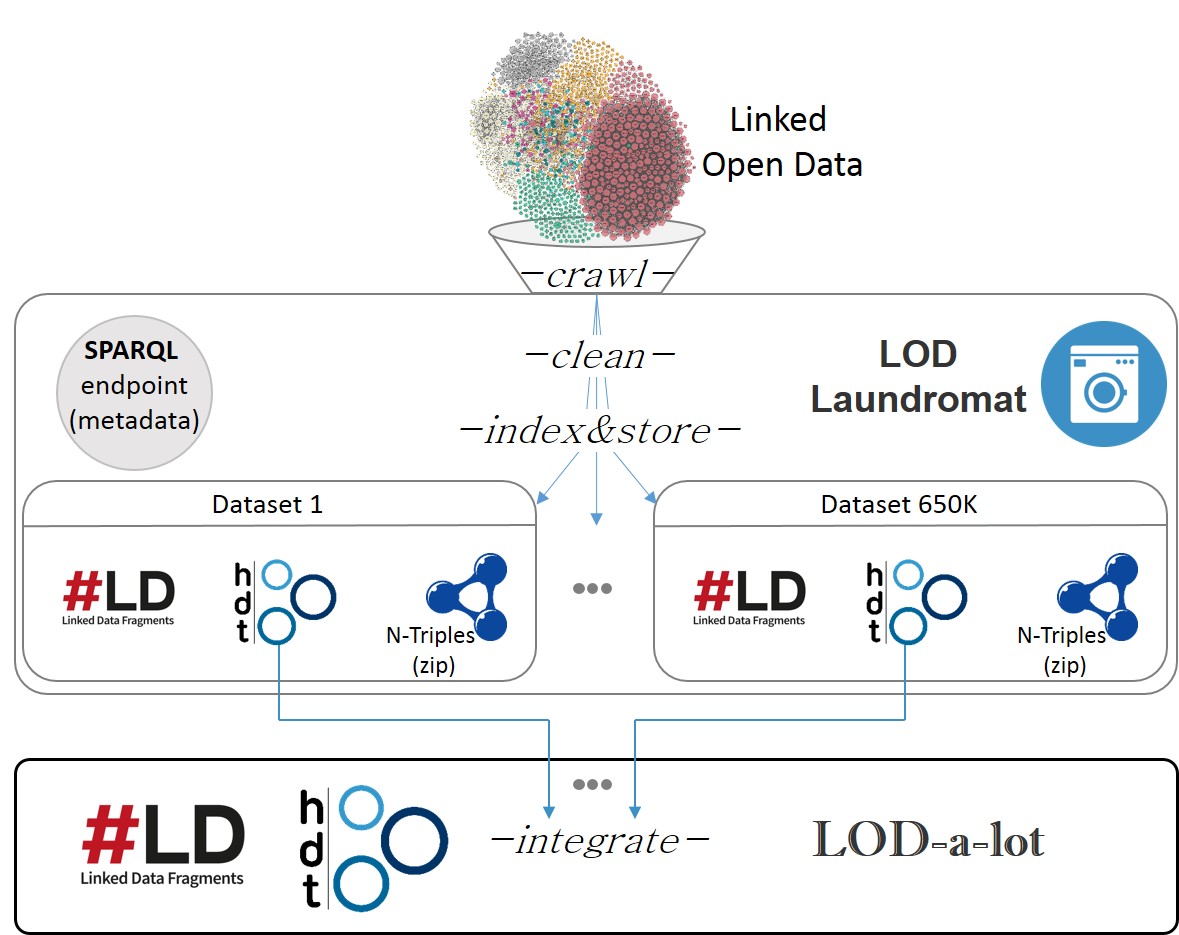
LOD-a-lot overview and data flow
LOD-a-lot is easy to deploy and only requires limited resources (524 GB of disk space and 15.7 GB of RAM), enabling web-scale repeatable experimentation and research from a high-end laptop.




